Müəllif: Azadə İmranzadə
Salam hörmətli oxucum,
Sizi növbəti yazımda xoş gördük.
Bu yazımızda siz Power BI-da data modellər barədə məlumatlar əldə edəcəksiniz. Data modelləşdirmə Power BI-ın 4 əsas (Dataların hazırlanmas və emalı, Modelləşdirmə, Vizuallaşdırma və analitika, Hesabatların paylaşılması) bölməsindən ikincisidir. Bu mərhələdə biz müxtəlif cədvəllərin bir-biri ilə əlaqələndirilməsini, müxtəlif hesablamaların və hesablanmış sütunların yaradılmasını həyata keçiririk. Bu əlaqələr düzgün qurulmadığı təqdirdə, bizim interaktiv vizuallardan istifadə edib analiz aparmaq imkanlarımız məhdudlaşır.
Data modelləşdirmə bizim ön fonda (ing. front-end) yaratdığımız analitik hesabatların arxa fonundakı (ing. back-end) vacib işlərini görür. Bu mərhələdə biz əlaqələri düzgün qurmasaq, doğru hesablamaları aparmasaq hesabatımız ya yanlış olacaq, ya da ümumiyyətlə effektiv işləməyəcəkdir. Optimal data modelin qurulması eyni zamanda bizim hesabatımızın Power BI-da performansına da təsir edəcək.
Data modelləşdirmə
Data modelləşdirmə datanın strukturunun, müxtəlif cədvəllər arasında qarşılıqlı əlaqələrin düzgün qurulmasını əks etdirən prosesdir.
Şəkil 1-də biz data modelə bir nümunə görə bilərik.

Power BI-da data modelləşdirmənin əsas konseptləri aşağıdakılardır:
- Data sxemləri (ing. Data schemas)
- Primary və foreign key (əsas və xarici açar) anlayışları
- Kardinallıq (ing. cardinality)
- Çarpaz filtr istiqamətləri (ing.cross-filter direction)
- Lookup və data cədvəlləri (eyni zamanda, Dim və fact cədvəlləri də adlanır)
Biz düzgün modelin necə qurulmasını öyrənmək üçün ilk öncə bir neçə əsas anlayışlara baxaq. Öncəki məqalələrdə qeyd etdiyimiz kimi, biz müxtəlif mənbələrdən cədvəlləri Power BI-daki hesabatımıza bağlayırıq. Bu cədvəllər sətir və sütunlardan ibarət olur və biz datanın transformasiya mərhələsində yalnız bizə lazım olan, yəni hesabatımıza bir şəkildə xidmət edəcək sütunları saxlayırıq. Hesabatımızda ümumiyyətlə istifadə etməyəcəyimiz sütunlar və sətirləri bu mərhələdə “təmizləyirik”. Bu proses datanın strukturunun düzgün qurulmasını əks etdirir. Bəs cədvəllər özləri bizə nə şəkildə xidmət edir?
Lookup və data cədvəlləri
Power BI-da qoşulduğumuz cədvəllərin bir qismi bizim üçün əsas “hadisələrin” (ing. events) baş verdiyi, üzərində analiz aparıb qarşı tərəfə çatdırmaq istədiyimiz məlumatların yer aldığı əsas cədvəllər olur.
Məsələn satış cədvəlləri, işçilərin işə qəbul və ya işdən çıxışının hesabatı, əmək haqqı ödənişləri hesabatı və s. Bu cədvəllərdə tarixlər üzrə müəyyən tranzaksiyalar, hərəkətlər baş verir və bəzən bunlar hər bir fərdə və ya məhsula aid unikal, bəzən isə təkrarlanan ola bilər. Yəni bir məhsuldan satış ildə 1 dəfə ola bilər, və ya 100 dəfə. Bir işçinin işdən çıxış məlumatı 1 dəfə baş verə bilər, və ya işə qəbul olub yenidən çıxmış ola bilər.
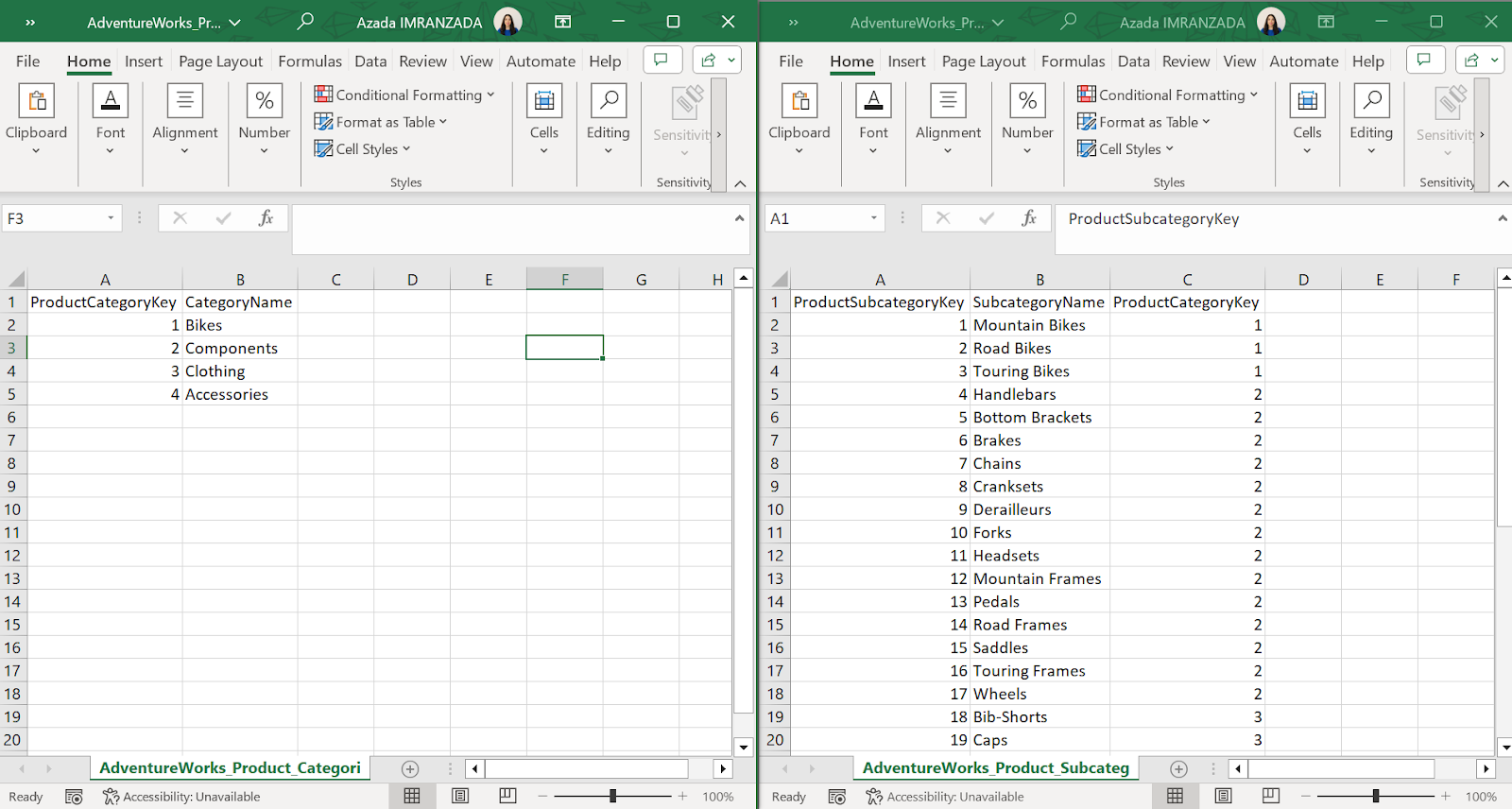
Bu cədvəllərə ingilis dilində “fact”, “data” və ya “event” cədvəlləri deyirlər. Bu cədvəlləri izah etməyimiz üçün bizə əlavə məlumatların saxlanıldığı izahedici cədvəllər, yəni “lookup” cədvəllər lazım olur. Onlara həm də “dim” (ing.dimension) cədvəllər deyilir. Həmin cədvəllərdə əsasən əsas cədvəllərimizdə olan məlumatlarla bağlı əlavə izahedici məlumatlar olur. Məsələn, şəkil 2-yə nəzər salsaq, fakt cədvəlində sifarişin sadəcə nömrəsi var, ikinci cədvəldə hər bir sifarişin nəyə aid olduğu və kateqoriyası, sonuncu cədvəldə isə məhsulla bağlı əlavə məlumatlar qeyd olunub.

Sual yarana bilər ki, biz bütün bu məlumatları ilkin cədvəlimizdə də saxlaya bilərik. Əlavə cədvəllərə ehtiyac niyə var ki? Doğrudur, biz bu məlumatları birləşdirə bilərik. Lakin, bu Power BI-ın işləmə prinsipinə performans nöqteyi-nəzərdən uyğun deyildir və bu şəkildə məlumat cədvəllərinin ayrıca saxlanılması məqsədəuyğundur. Həm də dim cədvəllər hər zaman yalnız bir data cədvəli izah eləmir, bəzən bir neçə data cədvələ də bağlanma ehtimallarını nəzərə alsaq, onları ayrı cədvəl şəklində saxlayıb modelimizi doğru qurmağımız daha məntiqlidir.
Biz Power BI-da fakt və dim cədvəllərinin arasında ortaq sütunlar əsasında əlaqələri yaradıb, modelimizi qururuq. Daha sonra həmin əlaqələr bizə imkan verir ki, istədiyimiz məlumatı istədiyimiz cədvəldən gətirək. Bəs bu necə baş verir?
Primary və foreign key (əsas və xarici açar) anlayışları
Qeyd etdik ki, ortaq sütunlar əsasında cədvəllərimizi əlaqələndiririk. Həmin ortaq dataların data dilində adlandırılması açar, yəni “key” şəklindədir. Bizim hər bir cədvəlimizdə unikal dəyərlərdən ibarət bir sütun olmalıdır, hansı ki, həmin sütunu əlaqələndirəcəyimiz digər cədvəldə eyni dəyərlərdən ibarət sütun vasitəsilə əlaqələndiririk və bu sütun “primary key” adlanır. İkinci cədvəldə bu dəyərlər unikal olmaya da bilər, yəni təkrarlana da bilər. Belə sütunlar “foreign key”, yəni xarici açar adlanır və onlar əsasən data və ya fakt cədvəllərdə olur. Əlbəttə, “lookup” cədvəllərdə də xarici açar sütun ola bilər.
Nümunə olaraq, şəkil 3-də yerləşən iki “lookup” cədvələ baxa bilərik. Kateqoriyalarla bağlı cədvəl subkateqoriyalarla bağlı cədvələ “ProductCategoryKey” açar sütunu ilə bağlanır, lakin diqqət etsək görərik ki, subkateqoriya cədvəlində həmin sütunda dəyərlər təkrarlanır. Yəni, həmin sütun artıq bu cədvəl üçün xarici açardır.
Kardinallıq
Əsas və xarici açar (ing. primary and foreign key) anlayışları ilə tanış olduqdan sonra data modelimizi qurmaq üçün bizə lazım olan bir digər anlayış da kardinallıq (ing. cardinality) anlayışıdır. Power BI-da modelləmə bölməsində “manage relationships”-əlaqələri idarə etmək üçün olan menyudan biz cədvəllərimiz arasında əlaqələr qururuq. Həmin əlaqələri özümüz tək-tək açar sütunları müəyyənləşdirərək də yarada bilərik, və ya elə proqram özü avtomatik müəyyənləşdirib edə bilər. Sonuncunu proqramın tənzimləmələrindən idarə edə bilirik.
Şəkil 4-də açılan pəncərədə biz əlaqələrin idarəedilməsi menyusunu görürük. Yeni əlaqələri biz “New” bölməsinə klikləyərək yaradırıq, əgər əlaqələri avtomatik müəyyənləşdirmək istəsək, “Autodetect” köməyimizə çata bilər. Bu əməliyyatı etdikdə, tövsiyə olunur ki, avtomatik yaradılmış əlaqələri nəzərdən keçirib, doğruluğunu yoxlayaq. Mövcud olan əlaqələri tənzimləmək üçün “edit” bölməsinə keçid edirik. “Delete” isə mövcud əlaqələri silir.

Şəkildə biz yaradılmış əlaqələri və cədvəllərdə əlaqələri göstərən xətlərin sonunda 1 və * işarələrini görürük. 1 rəqəmi o deməkdir ki, bizim cədvəlimizdə olan açar sütun əsas açardır, * işarəsi isə xarici açar sütunu vasitəsilə birləşdirilmənin həyata keçirildiyini bildirir. Yəni, əlaqənin 1 tərəfində açar sütunda dəyərlər unikaldır, * tərəfində isə dəyərlər təkrarlanır. Bu nümunə modeldə “many to one”, yəni çoxdan birə doğru əlaqələndirilmə adlanır.
Bundan başqa “one to one” və “many to many” kardinallıqlar da mövcuddur ki, “one to one” hər iki cədvəlimizdə sütunlarda olan dəyərlər unikal olduğunda mümkün olur. “Many to many” isə tövsiyə edilməyən bir kardinallıqdır və hər iki cədvəldə açar sütunlarda dəyərlərin təkrarlandığı halda qurulur.
Data sxemlər (ing. schemas)
Bizim şəkil 5-də gördüyümüz data modeli ulduz data sxemi adlanır və ən yaxşı data modeli sxemi hesab olunur. Təcrübəyə əsasən belə data modelinin daha effektiv olduğu və performansının daha yaxşı olduğu bildirilir. Bu modelin özəlliyi ondadır ki, əsas fakt cədvəlimiz mərkəzdə dayanır və digər dim cədvəllər əsas cədvəlin ətrafında ona birləşərək ulduzu xatırladır. Ulduz modeldən əlavə digər modellər də mövcuddur, lakin ulduz qədər geniş yayılmayıb və istifadə olunmur.
İkinci ən çox istifadə edilən model bizim şəkil 4-də gördüyümüz “snowflake”, yəni qar dənəciyi modelidir. Bu model o halda qurulur ki, bizim data cədvəli ilə əlaqələndirdiyimiz “lookup” cədvəlimiz bir başqa “lookup” cədvəlinə “one to many” kardinallıqla qoşulur. Yəni başqa bir “lookup” cədvəli digərini izah edir. Bizim nümunədə kateqoriya cədvəli subkateqoriya cədvəlinə bu şəkildə birləşdirilib, o da öz növbəsində məhsul cədvəlinə birləşdirilib. Sonda isə məhsul cədvəli mərkəzdəki satış cədvəlinə qoşulmuşdur. Bu halda satış cədvəlinə məlumat kateqoriya cədvəlindən, subkateqoriyaya doğru, oradan da məhsul cədvəlinə doğru axaraq gəlir.

Növbəti yazımızda görüşənədək.



